We want to empower every scientist and engineer to solve impossible problems because they have access to all the compute and analytical tools they need, any time they need them.
At SC'24 we’ll have our experts available for 1:1 meetings when they’re not staffing and supporting community events and hosting thousands of customers and partners at our booth. We’ll be hosting a networking event on Tuesday evening, with our goodfriends from NVIDIA, and welcoming everyone to Atlanta with the rest of the HPC on Arm community on Sunday evening.
Key events
- Sunday evening : Welcome to Atlanta from the Arm HPC User Group - drinks at Der Biergarten, 300 Marietta St NW, Atlanta, GA 30313 from 7-10pm
- Daily : Schedule a meeting with our experts and executives to discuss the problems you’re trying to solve.
- Tue @ 7pm : Come to the AWS and NVIDIA Mixer Reception @ the Hyatt Regency - PLEASE REGISTER so you’re not disappointed
- Wed @ 8am : Attend our Annual Cloud Breakfast for Research - this year discussing how difficult workloads that don’t scale well on-premises can move to the cloud, releasing capacity at home, and improving productivity for their end-users.
- Tue @ 6pm : Come to the Women in HPC Networking Reception which we’re supporting, along with our friends from AMD.
- Daily : our ask-an-architect area at Expo Booth #2501 to get help and knowledge from our cloud experts.
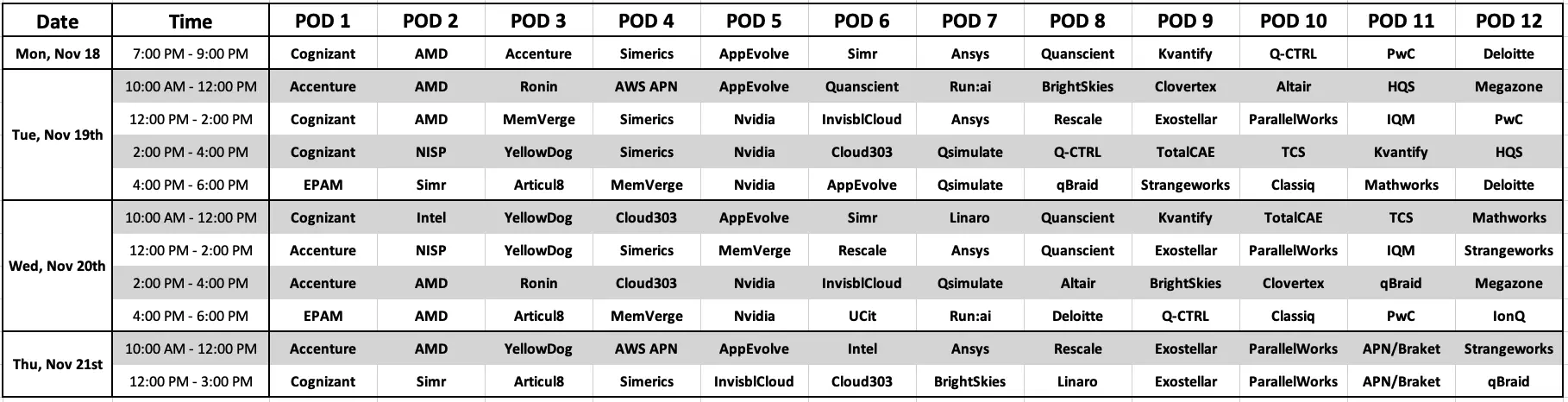
- Daily : dozens of our AWS HPC Partners will be at our Expo Booth (#2501) demo’ing and discussing their solutions and services (see the schedule below).
All-day live builder sessions to create with AWS HPC services

In the AWS Theatre our engineers will be building a complex HPC architecture live during the conference. You’ll see first hand the speed with which it’s possible to deploy completely new architectures and workflows, and how readily our recipes can be adapted to suit your environment.
10am-11am - Secure and successful foundation for HPC on AWS with NIST SP 800-223
This session lays out the foundational plumbing for a secure and scalable HPC environment on the cloud. We show architectural best-practices for cost optimization, security, and compliance alignment. We’ll show you how to achieve reproducibility using infrastructure-as-code techniques that will automate (and validate) your environments for deploying workloads.
11am-12pm - Re-imagining HPC with AWS Parallel Computing Service
We introduce AWS Parallel Computing Service (AWS PCS), a new managed service that transforms how organizations operate HPC environments in the cloud. We’ll demonstrate how PCS can eliminate operational overhead while preserving the familiar Slurm experience your users rely on. In real time, we’ll build a production-ready HPC cluster that integrates elastic storage from both NFS and high-performance Lustre, along with advanced compute capabilities like GPUs and our EFA networking. We’ll show you how a single infrastructure can efficiently support both large-scale simulation and model training workloads, simplify operations but maintaining the performance your applications demand.
12pm-1pm - Deploy a Terascale Lustre file system In minutes, not months
Come see a live build of a massive 1 Terabyte per second shared file system using Amazon FSx for Lustre. We’ll accelerate a large data-set from Amazon S3 and make use of file system semantics and metadata acceleration. You’ll get to see the simplicity of on-demand provisioning of an HPC cluster, too, faster than it took you to even specify the system you’re working on today.
1pm-2m - Providing workspaces and visualization tool for data analysis, and managing budgets
With our Slurm cluster managed with AWS Parallel Computing Service, we’ll explore different options for the end-user experience. We’ll first use a PCS-managed group of Login nodes to provide SSH access to the cluster. Next, we’ll illustrate how you can “Bring your own Login node” to the Research and Engineering Studio (RES) on AWS to provide individual or shared virtual graphical desktops. We’ll demonstrate visualization capabilities using Paraview in RES, powered by Amazon DCV, with hooks into Slurm’s job management.
2pm-3pm - Building your performant applications on different architectures on AWS
Now we’ll explore how to build, optimize, and run codes on our clusters making use of the Elastic Fabric Adaptor (EFA) which supports all our CPU and GPU architectures. We’ll show a software build of OpenFOAM using Spack. Then we’ll test this build on multiple architectures, and discuss how to validate that the build has been built to leverage best of each underlying architecture. Finally, we’ll submit a large-scale batch array of simulations that we’ll use later for trainng an ML model for rapid automotive design.
3pm-4pm - Cloud native HPC: Taking a different path to the same destination (an end-to-end AI 4 CAE workflow)
So far we’ve shown how to recreate a traditional HPC environment on the cloud, giving your users with prior knowledge of HPC systems a robust and performant system to leverage for their research. What if your users are researchers have no prior knowledge of HPC and instead prefer to work in data science environments like Jupyter Notebooks? This sessions shows how you can leverage a cloud-native scheduler, AWS Batch, and a popular data science workflow framework, Metaflow, to achieve massive scale for your workloads.
4pm-5pm - Using advanced HPC to change how we do engineering design
We can now work through the whole workflow we’ve been building to show you a glimpse of the near future. The simulation runs we kicked off will now serve as a training dataset for building a deep-learning surrogate model. Then we’ll take a hundred unseen geometries and do large-scale batch-inference using the pre-trained models, visualizing the results with our graphical desktops.
What we have built over the day is a complete end-to-end workflow for scientific simulations and machine-learning. The example we show you today is CFD, but this could be applied to many different scientific applications. Come and talk to us about your workflows.
Partners at the AWS Expo Booth #2501
We’ll have dozens of AWS APN Parners showing their solutions and services at our booth. All these partners work deeply with AWS and are trusted integrators, ISVs, and consulting partners that can work with you to solve practically any problem.